Wednesday, August 29, 2012
Switch
#include "iostream"
#include "iomanip"
using namespace std;
void main()
{
// Code 3, test switch fuction
bool quit = false;
char response;
cout << "Please input a, b, c,or q" << endl;
cin >> response;
while(quit == false)
{
cin >> response;
switch(response)
{
case 'a': cout <<"You chose 'a'" << setw(3) << endl; break;
case 'b': cout <<"You chose 'b'" << setw(3) << endl; break;
case 'c': cout <<"You chose 'c'" << setw(3) << endl; break;
case 'q': cout <<"You chose 'q', Program Will quit" << setw(3) << endl; quit = true; break;
default : cout <<"Please choose only a b c q" << endl;
}
};
while (getchar())
{
if (getchar()) break;
}///
//return 0;
}
Tuesday, August 28, 2012
IF 。。。。
| IF..... |
| IF you can keep your head when all about you Are losing theirs and blaming it on you, If you can trust yourself when all men doubt you, But make allowance for their doubting too; If you can wait and not be tired by waiting, Or being lied about, don't deal in lies, Or being hated, don't give way to hating, And yet don't look too good, nor talk too wise: If you can dream - and not make dreams your master; If you can think - and not make thoughts your aim; If you can meet with Triumph and Disaster And treat those two impostors just the same; If you can bear to hear the truth you've spoken Twisted by knaves to make a trap for fools, Or watch the things you gave your life to, broken, And stoop and build 'em up with worn-out tools: If you can make one heap of all your winnings And risk it on one turn of pitch-and-toss, And lose, and start again at your beginnings And never breathe a word about your loss; If you can force your heart and nerve and sinew To serve your turn long after they are gone, And so hold on when there is nothing in you Except the Will which says to them: 'Hold on!' If you can talk with crowds and keep your virtue, ' Or walk with Kings - nor lose the common touch, if neither foes nor loving friends can hurt you, If all men count with you, but none too much; If you can fill the unforgiving minute With sixty seconds' worth of distance run, Yours is the Earth and everything that's in it, And - which is more - you'll be a Man, my son! |
Friday, August 17, 2012
False positive and False negative
Type I error
A type I error, also known as an error of the first kind, occurs when the null hypothesis (H0) is true, but is rejected. It is asserting something that is absent, a false hit. A type I error may be compared with a so called false positive (a result that indicates that a given condition is present when it actually is not present) in tests where a single condition is tested for. Type I errors are philosophically a focus of skepticism and Occam's razor. A Type I error occurs when we believe a falsehood.[1] In terms of folk tales, an investigator may be "crying wolf" without a wolf in sight (raising a false alarm) (H0: no wolf).
The rate of the type I error is called the size of the test and denoted by the Greek letter  (alpha). It usually equals the significance level of a test. In the case of a simple null hypothesis is the probability of a type I error. If the null hypothesis is composite, is the maximum (supremum) of the possible probabilities of a type I error.
(alpha). It usually equals the significance level of a test. In the case of a simple null hypothesis is the probability of a type I error. If the null hypothesis is composite, is the maximum (supremum) of the possible probabilities of a type I error.
(alpha). It usually equals the significance level of a test. In the case of a simple null hypothesis is the probability of a type I error. If the null hypothesis is composite, is the maximum (supremum) of the possible probabilities of a type I error.False positive error
A false positive error, commonly called a "false alarm" is a result that indicates a given condition has been fulfilled, when it actually has not been fulfilled. In the case of "crying wolf" - the condition tested for was "is there a wolf near the herd?", the actual result was that there had not been a wolf near the herd. The shepherd wrongly indicated there was one, by calling "Wolf, wolf!".
A false positive error is a Type I error where the test is checking a single condition, and results in an affirmative or negative decision usually designated as "true or false".
Type II error
A type II error, also known as an error of the second kind, occurs when the null hypothesis is false, but it is erroneously accepted as true. It is missing to see what is present, a miss. A type II error may be compared with a so-called false negative (where an actual 'hit' was disregarded by the test and seen as a 'miss') in a test checking for a single condition with a definitive result of true or false. A Type II error is committed when we fail to believe a truth.[1] In terms of folk tales, an investigator may fail to see the wolf ("failing to raise an alarm"; see Aesop's story of The Boy Who Cried Wolf). Again, H0: no wolf.
The rate of the type II error is denoted by the Greek letter  (beta) and related to the power of a test (which equals
(beta) and related to the power of a test (which equals  ).
).
(beta) and related to the power of a test (which equals ).
What we actually call type I or type II error depends directly on the null hypothesis. Negation of the null hypothesis causes type I and type II errors to switch roles.
The goal of the test is to determine if the null hypothesis can be rejected. A statistical test can either reject (prove false) or fail to reject (fail to prove false) a null hypothesis, but never prove it true (i.e., failing to reject a null hypothesis does not prove it true).
False negative error
A false negative error is where a test result indicates that a condition failed, while it actually was successful. A common example is a guilty prisoner freed from jail. The condition: "Is the prisoner guilty?" actually had a positive result (yes, he is guilty). But the test failed to realize this, and wrongly decided the prisoner was not guilty.
A false negative error is a type II error occurring in test steps where a single condition is checked for and the result can either be positive or negative.
Example
As it is conjectured that adding fluoride to toothpaste protects against cavities, the null hypothesis of no effect is tested. When the null hypothesis is true (i.e., there is indeed no effect), but the data give rise to rejection of this hypothesis, falsely suggesting that adding fluoride is effective against cavities, a type I error has occurred.
A type II error occurs when the null hypothesis is false (i.e., adding fluoride is actually effective against cavities), but the data are such that the null hypothesis cannot be rejected, failing to prove the existing effect.
In colloquial usage type I error can be thought of as "convicting an innocent person" and type II error "letting a guilty person go free".
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:
| Null hypothesis (H0) is true | Null hypothesis (H0) is false | |
|---|---|---|
| Reject null hypothesis | Type I error False positive | Correct outcome True positive |
| Fail to reject null hypothesis | Correct outcome True negative | Type II error False negative |
Understanding Type I and Type II errors
From the Bayesian point of view, a type I error is one that looks at information that should not substantially change one's prior estimate of probability, but does. A type II error is one that looks at information which should change one's estimate, but does not. (Though the null hypothesis is not quite the same thing as one's prior estimate, it is, rather, one's pro forma prior estimate.)
Hypothesis testing is the art of testing whether a variation between two sample distributions can be explained by chance or not. In many practical applications type I errors are more delicate than type II errors. In these cases, care is usually focused on minimizing the occurrence of this statistical error. Suppose, the probability for a type I error is 1% , then there is a 1% chance that the observed variation is not true. This is called the level of significance, denoted with the Greek letter (alpha). While 1% might be an acceptable level of significance for one application, a different application can require a very different level. For example, the standard goal of six sigma is to achieve precision to 4.5 standard deviations above or below the mean. This means that only 3.4 parts per million are allowed to be deficient in a normally distributed process
(alpha). While 1% might be an acceptable level of significance for one application, a different application can require a very different level. For example, the standard goal of six sigma is to achieve precision to 4.5 standard deviations above or below the mean. This means that only 3.4 parts per million are allowed to be deficient in a normally distributed processTuesday, August 14, 2012
Radish: The Robotics Data Set Repository
Radish: The Robotics Data Set Repository
Standard data sets for the robotics community
Monday, August 13, 2012
Friday, August 10, 2012
How to Read a Scientific Research Paper
Reading research papers ("primary articles") is partly a matter of experience and skill, and partly learning the specific vocabulary of a field. First of all, DON'T PANIC! If you approach it step by step, even an impossible-looking paper can be understood.
1. Skimming. Skim the paper quickly, noting basics like headings, figures and the like. This takes just a few minutes. You're not trying to understand it yet, but just to get an overview.
2. Vocabulary. Go through the paper word by word and line by line, underlining or highlighting every word and phrase you don't understand. Don't worry if there are a lot of underlinings; you're still not trying to make sense of the article.
Now you have several things you might do with these vocabulary and concept questions, depending upon the kind of question each is. You can
- Look up simple words and phrases. Often the question is simply vocabulary--what's a lateral malleolus, or a christa, or the semilunar valve. A medical or biological dictionary is a good place to look for definitions. A textbook of physiology or anatomy may be a good source, because it give more complete explanations. Your ordinary shelf dictionary is not a good source, because the definitions may not be precise enough or may not reflect the way in which scientists use a word (for example "efficiency" has a common definition, but the physical definition is much more restricted.)
- Get an understanding from the context in which it is used. Often words that are used to describe the procedures used in an experiment can be understood from the context, and may be very specific to the paper you are reading. Examples are the "lithium-free control group" in a rat experiment or the "carotene extraction procedure" in a biochemical experiment. Of course, you should be careful when deciding that you understand a word from its context, because it might not mean what you think.
- Flag this phrase as belonging to one of the major concepts of the paper--it's bigger than a vocabulary question. For example, a paper about diet and cancer might refer to "risk reduction," which you would need to understand in context and in some depth.
3. Comprehension, section by section. Try to deal with all the words and phrases, although a few technical terms in the Methods section might remain. Now go back and read the whole paper, section by section, for comprehension.
In the Introduction, note how the context is set. What larger question is this a part of? The author should summarize and comment on previous research, and you should distinguish between previous research and the actual current study. What is the hypothesis of the paper and the ways this will be tested?
In the Methods, try to get a clear picture of what was done at each step. What was actually measured? It is a good idea to make an outline and/or sketch of the procedures and instruments. Keep notes of your questions; some of them may be simply technical, but others may point to more fundamental considerations that you will use for reflection and criticism below.
In Results look carefully at the figures and tables, as they are the heart of most papers. A scientist will often read the figures and tables before deciding whether it is worthwhile to read the rest of the article! What does it mean to "understand" a figure? You understand a figure when you can redraw it and explain it in plain English words.
The Discussion contains the conclusions that the author would like to draw from the data. In some papers, this section has a lot of interpretation and is very important. In any case, this is usually where the author reflects on the work and its meaning in relation to other findings and to the field in general.
4. Reflection and criticism. After you understand the article and can summarize it, then you can return to broader questions and draw your own conclusions. It is very useful to keep track of your questions as you go along, returning to see whether they have been answered. Often, the simple questions may contain the seeds of very deep thoughts about the work--for example, "Why did the authors use a questionnaire at the end of the month to find out about premenstrual tension? Wouldn't subjects forget or have trouble recalling?"
Here are some questions that may be useful in analyzing various kinds of research papers:
Introduction:
What is the overall purpose of the research?
How does the research fit into the context of its field? Is it, for example, attempting to settle a controversy? show the validity of a new technique? open up a new field of inquiry?
Do you agree with the author's rationale for studying the question in this way?
Methods:
Were the measurements appropriate for the questions the researcher was approaching?
Often, researchers need to use "indicators" because they cannot measure something directly--for example, using babies' birthweight to indicate nutritional status. Were the measures in this research clearly related to the variables in which the researchers (or you) were interested?
If human subjects were studied, do they fairly represent the populations under study?
Results
What is the one major finding?
Were enough of the data presented so that you feel you can judge for yourself how the experiment turned out?
Did you see patterns or trends in the data that the author did not mention? Were there problems that were not addressed?
Discussion
Do you agree with the conclusions drawn from the data?
Are these conclusions over-generalized or appropriately careful?
Are there other factors that could have influenced, or accounted for, the results?
What further experiments would you think of, to continue the research or to answer remaining questions?
Tuesday, August 7, 2012
Matlab plot to avi movie
t = 0:pi/200:2*pi;
y = sin(t);
% h = plot(t,y,'YDataSource','y');
h = plot(t,y);
i=0;
for k = 1:.1:10
i = i+1;
y = sin(t.*k);
set(h,'XData',t,'YData',y) % Evaluate y in the function workspace
drawnow;
M(i)=getframe;
pause(.05)
end
%%
movie2avi(M,'MatlabAnimation','fps',4,'compression','None','Quality',10)
语录
"如果不能做自己喜欢的事,那就喜欢上自己正在做的事吧!"
也许只有当你们被自己的努力感动得泪流满面时,你们的生命才能叫作美丽的生命……
人是习惯的动物,形成一定的习惯以后就不再去思考和改变。这种不愿思考和改变的状态是一种惰性,一种僵化的精神状态,它使我们陷入了惯性思维,使我们失去了改变现状的勇气。我们每天在交通最拥堵的时候挤公共汽车;每天上网进行着无聊的对话;每天晚上回到家把电视从一个频道换到另一个频道,这些都浪费了我们大量的时间。但我们却很少去改变,去认真地思考如何让生活过得更高效、更充实。其实只要我们稍加努力,就可能不断改进我们的生活。
静静想一想自己的生活和工作,看看是不是有地方可以改变一下,进而把自己的学习、生活和工作安排得更好、更简单,让自己的每一天更有意义!
只要活着,就是胜利。就像一棵树一样,活着,总能够慢慢长大.
金字塔如果拆开了,只不过是一堆散乱的石头;日子如果过得没有目标,就只是几段散乱的岁月,但如果把一种努力凝聚到每一日,去实现一个梦想,散乱的日子就积成了生命的永恒。
Monday, August 6, 2012
Split widecreen monitor
So in order to split your display down the middle either horizontally or vertically, first open two applications, let’s say Word and Excel. Now click on one of the tabs in the Windows Taskbar and then press and hold the CNTRL key on your keyboard. While holding down the CNTRL key, click on the other tab in the Taskbar. They should both be selected now (they should have a darker background than the other tabs).

Now that both applications are selected in the Taskbar, right-click on either one and choose Tile Vertically from the options.
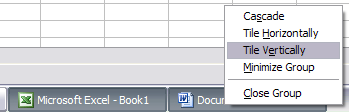
And viola! You should now have Word on one side of the screen and Excel on the other side! If you want them in landscape view rather than portrait view, just choose Tile Horizontally.
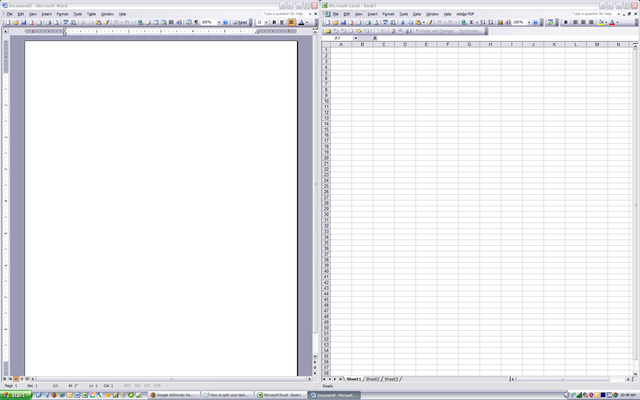
You can also split your screen three ways or more by simply selecting more applications in the Taskbar! Pretty easy! So that’s what is involved to split your screen if you have one monitor.
Subscribe to:
Posts (Atom)